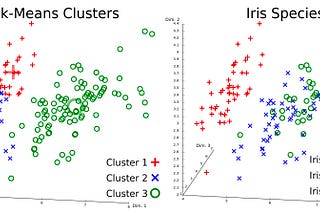
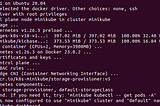
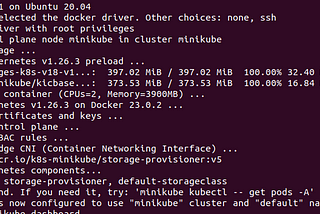
Spark — Running K MeansMost frequently asked question — how do I run ML algorithm on huge set of data?May 30, 2023May 30, 2023
Spark — Reading data from fileIf you are not familiar with running spark on minikube, then I recommend reading my previous post Spark on Minikube.May 30, 2023May 30, 2023
Spark on MinikubeKubernetes is by far the most commonly used orchestration engine for containers. Minikube is local Kubernetes, focusing on deployment of…Apr 7, 2023Apr 7, 2023
Database Benchmarks — Transaction Processing PerformanceIt is interesting to discover that the TPC in TPC.ORG — the industry benchmark for database (and whole lot more) benchmark stands for…Jan 7, 2022Jan 7, 2022
DynamoDB + Python CookbookLot has been written about DynamoDB & Python. However when creating a simple application, it is difficult to find required resources in…Jan 3, 2021Jan 3, 2021
DPC — Create TableFor Details: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GettingStarted.Python.01.htmlJan 3, 2021Jan 3, 2021